Tomcat7.0源码分析——server.xml文件的加载与解析
本文共 27300 字,大约阅读时间需要 91 分钟。
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/beliefer/article/details/51035923
前言
作为Java程序员,对于Tomcat的server.xml想必都不陌生。本文基于Tomcat7.0的Java源码,对server.xml文件是如何加载和解析进行分析。加载过程分析
Bootstrap的load方法用于加载Tomcat的server.xml,实际是通过反射调用Catalina的load方法,代码如下:/** * Load daemon. */ private void load(String[] arguments) throws Exception { // Call the load() method String methodName = "load"; Object param[]; Class paramTypes[]; if (arguments==null || arguments.length==0) { paramTypes = null; param = null; } else { paramTypes = new Class[1]; paramTypes[0] = arguments.getClass(); param = new Object[1]; param[0] = arguments; } Method method = catalinaDaemon.getClass().getMethod(methodName, paramTypes); if (log.isDebugEnabled()) log.debug("Calling startup class " + method); method.invoke(catalinaDaemon, param); } Catalina的load方法实现如下: /** * Start a new server instance. */ public void load() { long t1 = System.nanoTime(); initDirs(); // Before digester - it may be needed initNaming(); // Create and execute our Digester Digester digester = createStartDigester(); InputSource inputSource = null; InputStream inputStream = null; File file = null; try { file = configFile(); inputStream = new FileInputStream(file); inputSource = new InputSource("file://" + file.getAbsolutePath()); } catch (Exception e) { // Ignore } if (inputStream == null) { try { inputStream = getClass().getClassLoader() .getResourceAsStream(getConfigFile()); inputSource = new InputSource (getClass().getClassLoader() .getResource(getConfigFile()).toString()); } catch (Exception e) { // Ignore } } // This should be included in catalina.jar // Alternative: don't bother with xml, just create it manually. if( inputStream==null ) { try { inputStream = getClass().getClassLoader() .getResourceAsStream("server-embed.xml"); inputSource = new InputSource (getClass().getClassLoader() .getResource("server-embed.xml").toString()); } catch (Exception e) { // Ignore } } if ((inputStream == null) && (file != null)) { log.warn("Can't load server.xml from " + file.getAbsolutePath()); if (file.exists() && !file.canRead()) { log.warn("Permissions incorrect, read permission is not allowed on the file."); } return; } try { inputSource.setByteStream(inputStream); digester.push(this); digester.parse(inputSource); inputStream.close(); } catch (Exception e) { log.warn("Catalina.start using " + getConfigFile() + ": " , e); return; } // Stream redirection initStreams(); // Start the new server try { getServer().init(); } catch (LifecycleException e) { if (Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) throw new java.lang.Error(e); else log.error("Catalina.start", e); } long t2 = System.nanoTime(); if(log.isInfoEnabled()) log.info("Initialization processed in " + ((t2 - t1) / 1000000) + " ms"); } 这里对上述代码进行分析: 1) initDirs方法用于对catalina.home和catalina.base的一些检查工作。 2) initNaming方法给系统设置java.naming.factory.url.pkgs和java.naming.factory.initial。在创建JNDI上下文时,使用Context.INITIAL_CONTEXT_FACTORY("java.naming.factory.initial")属性,来指定创建JNDI上下文的工厂类;Context.URL_PKG_PREFIXES("java.naming.factory.url.pkgs")用在查询url中包括scheme方法id时创建对应的JNDI上下文,例如查询"java:/jdbc/test1"等类似查询上,即以冒号":"标识的shceme。Context.URL_PKG_PREFIXES属性值有多个java 包(package)路径,其中以冒号":"分隔各个包路径,这些包路径中包括JNDI相关实现类。当在JNDI上下文中查找"java:"这类包括scheme方案ID的url时,InitialContext类将优先查找Context.URL_PKG_PREFIXES属性指定的包路径中是否存在 scheme+"."+scheme + "URLContextFactory"工厂类(需要实现ObjectFactory接口),如果存在此工厂类,则调用此工厂类的getObjectInstance方法获得此scheme方案ID对应的jndi上下文,再在此上下文中继续查找对应的url。 3) createStartDigester方法创建并配置将要用来启动的Digester实例,并且设置一些列Rule,具体映射到server.xml。 4) 使用FileInputStream获取conf/server.xml配置文件输入流。 5) 将FileInputStream封装为InputSource,并且调用Digester的parse方法进行解析。 6) initStreams对输出流、错误流重定向。 7) 初始化server,具体实现本文不做分析。
规则
在正式介绍Digester的parse方法的解析过程前,我们先来掌握一些规则相关的内容。Tomcat将server.xml文件中的所有元素上的属性都抽象为Rule,以Server元素为例,在内存中对应Server实例,Server实例的属性值就来自于Server元素的属性值。通过对规则(Rule)的应用,最终改变Server实例的属性值。 Rule是一个抽象类,其中定义了以下方法:- getDigester:获取Digester实例;
- setDigester:设置Digester实例;
- getNamespaceURI:获取Rule所在的相对命名空间URI;
- setNamespaceURI:设置Rule所在的相对命名空间URI;
- begin(String namespace, String name, Attributes attributes):此方法在遇到一个匹配的XML元素的开头时被调用,如:<Server>。
- body(String namespace, String name, String text):在遇到匹配XML元素的body时,此方法被调用,如进入<Server>标签内部时。
- end(String namespace, String name):此方法在遇到一个匹配的XML元素的末尾时被调用。如:</Server>。
 这里以最常用的几个规则表示Rule的类继承体系,如下图:
这里以最常用的几个规则表示Rule的类继承体系,如下图: 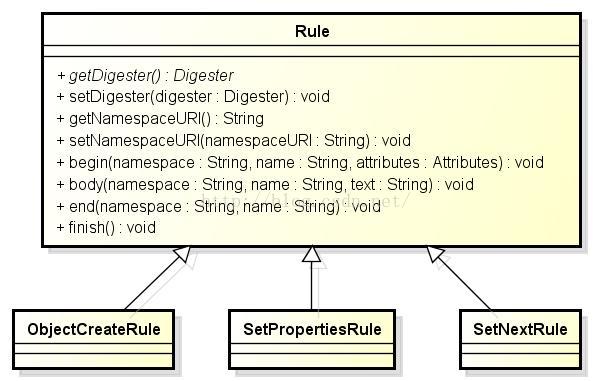
SAX(Simple API for XML)
相比于 DOM 而言 SAX 是一种速度更快,更有效,占用内存更少的解析 XML 文件的方法。它是逐行扫描,可以做到边扫描边解析,因此 SAX 可以在解析文档的任意时刻停止解析。SAX 是基于事件驱动的。SAX 不用解析完整个文档,在按内容顺序解析文档过程中, SAX 会判断当前读到的字符是否符合 XML 文件语法中的某部分。如果符合某部分,则会触发事件。所谓触发事件,就是调用一些回调方法。在用 SAX 解析 xml 文档时候,在读取到文档开始和结束标签时候就会回调一个事件,在读取到其他节点与内容时候也会回调一个事件。在 SAX 接口中,事件源是 org.xml.sax 包中的 XMLReader ,它通过 parser() 方法来解析 XML 文档,并产生事件。事件处理器是 org.xml.sax 包中 ContentHander 、 DTDHander 、 ErrorHandler ,以及 EntityResolver 这 4 个接口。| 事件处理器 | 事件处理器处理的事件 | XMLReader 注册方法 |
| ContentHander | XML 文档的开始与结束 | setContentHandler(ContentHandler h) |
| DTDHander | 处理 DTD 解析 | setDTDHandler(DTDHandler h) |
| ErrorHandler | 处理 XML 时产生的错误 | setErrorHandler(ErrorHandler h) |
| EntityResolver | 处理外部实体 | setEntityResolver(EntityResolver e) |
- startDocument() :当遇到文档的开头的时候,调用这个方法,可以在其中做一些预处理的工作。
- endDocument() :当文档结束的时候,调用这个方法,可以在其中做一些善后的工作。
- startElement(String namespaceURI, String localName,String qName, Attributes atts):当读到开始标签的时候,会调用这个方法。 namespaceURI 就是命名空间, localName 是不带命名空间前缀的标签名, qName 是带命名空间前缀的标签名。通过 atts 可以得到所有的属性名和相应的值。
- endElement(String uri, String localName, String name):在遇到结束标签的时候,调用这个方法。
- characters(char[] ch, int start, int length):这个方法用来处理在 XML 文件中读到的内容。例如: <high data="30"/> 主要目的是获取 high 标签中的值。
解析过程分析
在介绍Catalina的load方法时,遇见了createStartDigester方法,它的实现如代码清单1: 代码清单1
/** * Create and configure the Digester we will be using for startup. */ protected Digester createStartDigester() { long t1=System.currentTimeMillis(); // Initialize the digester Digester digester = new Digester(); digester.setValidating(false); digester.setRulesValidation(true); HashMap , List > fakeAttributes = new HashMap , List >(); ArrayList attrs = new ArrayList (); attrs.add("className"); fakeAttributes.put(Object.class, attrs); digester.setFakeAttributes(fakeAttributes); digester.setClassLoader(StandardServer.class.getClassLoader()); // Configure the actions we will be using digester.addObjectCreate("Server", "org.apache.catalina.core.StandardServer", "className"); digester.addSetProperties("Server"); digester.addSetNext("Server", "setServer", "org.apache.catalina.Server"); digester.addObjectCreate("Server/GlobalNamingResources", "org.apache.catalina.deploy.NamingResources"); digester.addSetProperties("Server/GlobalNamingResources"); digester.addSetNext("Server/GlobalNamingResources", "setGlobalNamingResources", "org.apache.catalina.deploy.NamingResources"); digester.addObjectCreate("Server/Listener", null, // MUST be specified in the element "className"); digester.addSetProperties("Server/Listener"); digester.addSetNext("Server/Listener", "addLifecycleListener", "org.apache.catalina.LifecycleListener"); digester.addObjectCreate("Server/Service", "org.apache.catalina.core.StandardService", "className"); digester.addSetProperties("Server/Service"); digester.addSetNext("Server/Service", "addService", "org.apache.catalina.Service"); digester.addObjectCreate("Server/Service/Listener", null, // MUST be specified in the element "className"); digester.addSetProperties("Server/Service/Listener"); digester.addSetNext("Server/Service/Listener", "addLifecycleListener", "org.apache.catalina.LifecycleListener"); //Executor digester.addObjectCreate("Server/Service/Executor", "org.apache.catalina.core.StandardThreadExecutor", "className"); digester.addSetProperties("Server/Service/Executor"); digester.addSetNext("Server/Service/Executor", "addExecutor", "org.apache.catalina.Executor"); digester.addRule("Server/Service/Connector", new ConnectorCreateRule()); digester.addRule("Server/Service/Connector", new SetAllPropertiesRule(new String[]{"executor"})); digester.addSetNext("Server/Service/Connector", "addConnector", "org.apache.catalina.connector.Connector"); digester.addObjectCreate("Server/Service/Connector/Listener", null, // MUST be specified in the element "className"); digester.addSetProperties("Server/Service/Connector/Listener"); digester.addSetNext("Server/Service/Connector/Listener", "addLifecycleListener", "org.apache.catalina.LifecycleListener"); // Add RuleSets for nested elements digester.addRuleSet(new NamingRuleSet("Server/GlobalNamingResources/")); digester.addRuleSet(new EngineRuleSet("Server/Service/")); digester.addRuleSet(new HostRuleSet("Server/Service/Engine/")); digester.addRuleSet(new ContextRuleSet("Server/Service/Engine/Host/")); digester.addRuleSet(ClusterRuleSetFactory.getClusterRuleSet("Server/Service/Engine/Host/Cluster/")); digester.addRuleSet(new NamingRuleSet("Server/Service/Engine/Host/Context/")); // When the 'engine' is found, set the parentClassLoader. digester.addRule("Server/Service/Engine", new SetParentClassLoaderRule(parentClassLoader)); digester.addRuleSet(ClusterRuleSetFactory.getClusterRuleSet("Server/Service/Engine/Cluster/")); long t2=System.currentTimeMillis(); if (log.isDebugEnabled()) log.debug("Digester for server.xml created " + ( t2-t1 )); return (digester); } 代码清单1首先创建Digester,Digester继承了DefaultHandler,而DefaultHandler默认实现了ContentHander、DTDHander、ErrorHandler及EntityResolver 这4个接口,代码如下: public class DefaultHandler implements EntityResolver, DTDHandler, ContentHandler, ErrorHandler如果阅读DefaultHandler的源码,发现它的所有实现都是空实现,看来要发挥解析作用,只能依靠Digester自己了,见代码清单2。
代码清单2
@Override public void startDocument() throws SAXException { if (saxLog.isDebugEnabled()) { saxLog.debug("startDocument()"); } configure(); } @Override public void endDocument() throws SAXException { if (saxLog.isDebugEnabled()) { if (getCount() > 1) { saxLog.debug("endDocument(): " + getCount() + " elements left"); } else { saxLog.debug("endDocument()"); } } while (getCount() > 1) { pop(); } // Fire "finish" events for all defined rules Iterator rules = getRules().rules().iterator(); while (rules.hasNext()) { Rule rule = rules.next(); try { rule.finish(); } catch (Exception e) { log.error("Finish event threw exception", e); throw createSAXException(e); } catch (Error e) { log.error("Finish event threw error", e); throw e; } } // Perform final cleanup clear(); } @Override public void startElement(String namespaceURI, String localName, String qName, Attributes list) throws SAXException { boolean debug = log.isDebugEnabled(); if (saxLog.isDebugEnabled()) { saxLog.debug("startElement(" + namespaceURI + "," + localName + "," + qName + ")"); } // Parse system properties list = updateAttributes(list); // Save the body text accumulated for our surrounding element bodyTexts.push(bodyText); if (debug) { log.debug(" Pushing body text '" + bodyText.toString() + "'"); } bodyText = new StringBuilder(); // the actual element name is either in localName or qName, depending // on whether the parser is namespace aware String name = localName; if ((name == null) || (name.length() < 1)) { name = qName; } // Compute the current matching rule StringBuilder sb = new StringBuilder(match); if (match.length() > 0) { sb.append('/'); } sb.append(name); match = sb.toString(); if (debug) { log.debug(" New match='" + match + "'"); } // Fire "begin" events for all relevant rules List rules = getRules().match(namespaceURI, match); matches.push(rules); if ((rules != null) && (rules.size() > 0)) { for (int i = 0; i < rules.size(); i++) { try { Rule rule = rules.get(i); if (debug) { log.debug(" Fire begin() for " + rule); } rule.begin(namespaceURI, name, list); } catch (Exception e) { log.error("Begin event threw exception", e); throw createSAXException(e); } catch (Error e) { log.error("Begin event threw error", e); throw e; } } } else { if (debug) { log.debug(" No rules found matching '" + match + "'."); } } } @Override public void endElement(String namespaceURI, String localName, String qName) throws SAXException { boolean debug = log.isDebugEnabled(); if (debug) { if (saxLog.isDebugEnabled()) { saxLog.debug("endElement(" + namespaceURI + "," + localName + "," + qName + ")"); } log.debug(" match='" + match + "'"); log.debug(" bodyText='" + bodyText + "'"); } // Parse system properties bodyText = updateBodyText(bodyText); // the actual element name is either in localName or qName, depending // on whether the parser is namespace aware String name = localName; if ((name == null) || (name.length() < 1)) { name = qName; } // Fire "body" events for all relevant rules List rules = matches.pop(); if ((rules != null) && (rules.size() > 0)) { String bodyText = this.bodyText.toString(); for (int i = 0; i < rules.size(); i++) { try { Rule rule = rules.get(i); if (debug) { log.debug(" Fire body() for " + rule); } rule.body(namespaceURI, name, bodyText); } catch (Exception e) { log.error("Body event threw exception", e); throw createSAXException(e); } catch (Error e) { log.error("Body event threw error", e); throw e; } } } else { if (debug) { log.debug(" No rules found matching '" + match + "'."); } if (rulesValidation) { log.warn(" No rules found matching '" + match + "'."); } } // Recover the body text from the surrounding element bodyText = bodyTexts.pop(); if (debug) { log.debug(" Popping body text '" + bodyText.toString() + "'"); } // Fire "end" events for all relevant rules in reverse order if (rules != null) { for (int i = 0; i < rules.size(); i++) { int j = (rules.size() - i) - 1; try { Rule rule = rules.get(j); if (debug) { log.debug(" Fire end() for " + rule); } rule.end(namespaceURI, name); } catch (Exception e) { log.error("End event threw exception", e); throw createSAXException(e); } catch (Error e) { log.error("End event threw error", e); throw e; } } } // Recover the previous match expression int slash = match.lastIndexOf('/'); if (slash >= 0) { match = match.substring(0, slash); } else { match = ""; } } 代码清单1中创建完Digester后,会调用addObjectCreate、addSetProperties、addSetNext方法陆续添加很多Rule,这些方法的实现如代码清单3: public void addObjectCreate(String pattern, String className, String attributeName) { addRule(pattern, new ObjectCreateRule(className, attributeName)); } public void addSetProperties(String pattern) { addRule(pattern, new SetPropertiesRule()); } public void addSetNext(String pattern, String methodName, String paramType) { addRule(pattern, new SetNextRule(methodName, paramType)); } 从上述代码我们看到这三个方法分别创建ObjectCreateRule、SetPropertiesRule及SetNextRule。为了简化理解我们以Server相关的Rule为例,如代码清单4: 代码清单4
digester.addObjectCreate("Server", "org.apache.catalina.core.StandardServer", "className"); digester.addSetProperties("Server"); digester.addSetNext("Server", "setServer", "org.apache.catalina.Server"); 根据代码清单3的实现,我们知道最终会创建ObjectCreateRule、SetPropertiesRule及SetNextRule,并且调用addRule方法。addRule方法首先调用getRules方法获取RulesBase,然后调用RulesBase的add方法。addRule方法的实现如下: public void addRule(String pattern, Rule rule) { rule.setDigester(this); getRules().add(pattern, rule); } public Rules getRules() { if (this.rules == null) { this.rules = new RulesBase(); this.rules.setDigester(this); } return (this.rules); } RulesBase的add方法的实现如下: public void add(String pattern, Rule rule) { // to help users who accidently add '/' to the end of their patterns int patternLength = pattern.length(); if (patternLength>1 && pattern.endsWith("/")) { pattern = pattern.substring(0, patternLength-1); } List list = cache.get(pattern); if (list == null) { list = new ArrayList (); cache.put(pattern, list); } list.add(rule); rules.add(rule); if (this.digester != null) { rule.setDigester(this.digester); } if (this.namespaceURI != null) { rule.setNamespaceURI(this.namespaceURI); } } 其中,cache的数据结构为HashMap<String,List<Rule>>,每个键值维护一个List<Rule>,由此可知,对Server标签来说,对应的Rule列表为ObjectCreateRule、SetPropertiesRule及SetNextRule。 Digester解析XML的入口是其parse方法,其处理步骤如下: 1.创建XMLReader ; 2.使用XMLReader解析XML。 parse方法的代码如下: public Object parse(InputSource input) throws IOException, SAXException { configure(); getXMLReader().parse(input); return (root); } getXMLReader方法调用getParser创建SAXParser ,然后调用SAXParser 的getXMLReader方法创建XMLReader ,代码如下: public XMLReader getXMLReader() throws SAXException { if (reader == null){ reader = getParser().getXMLReader(); } reader.setDTDHandler(this); reader.setContentHandler(this); if (entityResolver == null){ reader.setEntityResolver(this); } else { reader.setEntityResolver(entityResolver); } reader.setErrorHandler(this); return reader; } getParser方法调用getFactory方法创建SAXParserFactory,然后调用SAXParserFactory的newSAXParser方法创建SAXParser ,代码如下: public SAXParser getParser() { // Return the parser we already created (if any) if (parser != null) { return (parser); } // Create a new parser try { parser = getFactory().newSAXParser(); } catch (Exception e) { log.error("Digester.getParser: ", e); return (null); } return (parser); } getFactory方法使用SAX的API生成SAXParserFactory实例,代码如下: public SAXParserFactory getFactory() throws SAXNotRecognizedException, SAXNotSupportedException, ParserConfigurationException { if (factory == null) { factory = SAXParserFactory.newInstance(); factory.setNamespaceAware(namespaceAware); factory.setValidating(validating); if (validating) { // Enable DTD validation factory.setFeature( "http://xml.org/sax/features/validation", true); // Enable schema validation factory.setFeature( "http://apache.org/xml/features/validation/schema", true); } } return (factory); } XMLReader解析XML时,会生成事件,回调Digester的startDocument方法,解析的第一个元素是Server,此时回调Digester的startElement方法,入参Attributes list即Server上的属性,如port、shutdown等,入参qName即为Server。startElement方法的代码如下: @Override public void startElement(String namespaceURI, String localName, String qName, Attributes list) throws SAXException { boolean debug = log.isDebugEnabled(); if (saxLog.isDebugEnabled()) { saxLog.debug("startElement(" + namespaceURI + "," + localName + "," + qName + ")"); } // Parse system properties list = updateAttributes(list); // Save the body text accumulated for our surrounding element bodyTexts.push(bodyText); if (debug) { log.debug(" Pushing body text '" + bodyText.toString() + "'"); } bodyText = new StringBuilder(); // the actual element name is either in localName or qName, depending // on whether the parser is namespace aware String name = localName; if ((name == null) || (name.length() < 1)) { name = qName; } // Compute the current matching rule StringBuilder sb = new StringBuilder(match); if (match.length() > 0) { sb.append('/'); } sb.append(name); match = sb.toString(); if (debug) { log.debug(" New match='" + match + "'"); } // Fire "begin" events for all relevant rules List rules = getRules().match(namespaceURI, match); matches.push(rules); if ((rules != null) && (rules.size() > 0)) { for (int i = 0; i < rules.size(); i++) { try { Rule rule = rules.get(i); if (debug) { log.debug(" Fire begin() for " + rule); } rule.begin(namespaceURI, name, list); } catch (Exception e) { log.error("Begin event threw exception", e); throw createSAXException(e); } catch (Error e) { log.error("Begin event threw error", e); throw e; } } } else { if (debug) { log.debug(" No rules found matching '" + match + "'."); } } } startElement方法的处理步骤如下: 1.match刚开始为空字符串,拼接Server后变为Server。 2.调用RulesBase的match方法,返回cache中按照键值Server匹配的ObjectCreateRule、SetPropertiesRule及SetNextRule。 3.循环列表依次遍历ObjectCreateRule、SetPropertiesRule及SetNextRule,并调用它们的begin方法。 ObjectCreateRule的begin方法将生成Server的实例(默认为"org.apache.catalina.core.StandardServer",用户可以通过给Server标签指定className使用其它Server实现),最后将Server的实例压入Digester的栈中,代码如下: @Override public void begin(String namespace, String name, Attributes attributes) throws Exception { // Identify the name of the class to instantiate String realClassName = className; if (attributeName != null) { String value = attributes.getValue(attributeName); if (value != null) { realClassName = value; } } if (digester.log.isDebugEnabled()) { digester.log.debug("[ObjectCreateRule]{" + digester.match + "}New " + realClassName); } // Instantiate the new object and push it on the context stack Class clazz = digester.getClassLoader().loadClass(realClassName); Object instance = clazz.newInstance(); digester.push(instance); } SetPropertiesRule的begin方法首先将刚才压入栈中的Server实例出栈,然后给Server实例设置各个属性值,如port、shutdown等,代码如下: @Override public void begin(String namespace, String theName, Attributes attributes) throws Exception { // Populate the corresponding properties of the top object Object top = digester.peek(); if (digester.log.isDebugEnabled()) { if (top != null) { digester.log.debug("[SetPropertiesRule]{" + digester.match + "} Set " + top.getClass().getName() + " properties"); } else { digester.log.debug("[SetPropertiesRule]{" + digester.match + "} Set NULL properties"); } } // set up variables for custom names mappings int attNamesLength = 0; if (attributeNames != null) { attNamesLength = attributeNames.length; } int propNamesLength = 0; if (propertyNames != null) { propNamesLength = propertyNames.length; } for (int i = 0; i < attributes.getLength(); i++) { String name = attributes.getLocalName(i); if ("".equals(name)) { name = attributes.getQName(i); } String value = attributes.getValue(i); // we'll now check for custom mappings for (int n = 0; n SetNextRule的begin不做什么动作。当遇到Server的结束标签时,还会依次调用ObjectCreateRule、SetPropertiesRule及SetNextRule的end方法,不再赘述。所有元素的解析都与Server标签同理,最终将server.xml文件中设置的元素及其属性值,构造出Tomcat中的容器,如:Server、Service、Connector等。
后记:个人总结整理的《深入理解Spark:核心思想与源码分析》一书现在已经正式出版上市,目前京东、当当、天猫等网站均有销售,欢迎感兴趣的同学购买。

京东:
当当:
你可能感兴趣的文章
[T-SQL]从变量与数据类型说起
查看>>
稀疏自动编码之反向传播算法(BP)
查看>>
二叉搜索树转换成双向链表
查看>>
会员数据化运营
查看>>
WebLogic和Tomcat的区别
查看>>
java类中 获取服务器的IP 端口
查看>>
调用约定__stdcall / __cdecl
查看>>
occActiveX - ActiveX with OpenCASCADE
查看>>
redmine
查看>>
css 序
查看>>
DirectshowLib摄像头拍照的”未找到可用于建立连接的介质筛选器组合“ 解决办法...
查看>>
Django之用户认证组件
查看>>
python如何使用 os.path.exists()--Learning from stackoverflow ...
查看>>
wcf-1
查看>>
关于分区表的初探
查看>>
Xcode 6 下添加pch头文件
查看>>
三种简单排序
查看>>
curl 向远程服务器传输file文件
查看>>
[Java]读取文件方法大全
查看>>
【NopCommerce源码架构学习-二】单例模式实现代码分析
查看>>